import axelrod as axl
players = (axl.Cooperator(), axl.Random())
match = axl.Match(players, turns=5)
results = match.play()
results
[(C, C), (C, C), (C, C), (C, D), (C, C)]
Below is an easy way to get scores without having regard for the specifics. Generally when one player undercuts the other then they are collectively worse off than had they cooperated.
scores = match.scores()
scores
[(3, 3), (3, 3), (3, 3), (0, 5), (3, 3)]
match.final_score()
(12, 17)
match.final_score_per_turn()
(2.4, 3.4)
This would always be unchanging and is determined by the nature of the player rather than the random results the player achieves. The playr would win 50% of the time.
match.winner()
Random: 0.5
match.cooperation() # The count of cooperations
(5, 4)
match.normalised_cooperation()
(1.0, 0.8)
import axelrod as axl
players = (axl.Cooperator(), axl.Alternator())
match = axl.Match(players, 25)
match.play()
[(C, C),
(C, D),
(C, C),
(C, D),
(C, C),
(C, D),
(C, C),
(C, D),
(C, C),
(C, D),
(C, C),
(C, D),
(C, C),
(C, D),
(C, C),
(C, D),
(C, C),
(C, D),
(C, C),
(C, D),
(C, C),
(C, D),
(C, C),
(C, D),
(C, C)]
print(match.sparklines())
█████████████████████████
█ █ █ █ █ █ █ █ █ █ █ █ █
The library was primarily created to stuy the interactions between strategies in a round robin tournament. A tournament where each strategy play against all opponents and the strategy with the highest score is the winner of the tournament. Here we will cover how we can easily create a very simple IPD (Iterated Prisoners Dillema) tournament.
players = [axl.Cooperator(), axl.Defector(), axl.Random(),
axl.TitForTat(), axl.Grumpy(), axl.Alternator()]
tournament = axl.Tournament(players=players)
tournament.turns # default value of turns
200
tournament.repetitions # default value of repititions
10
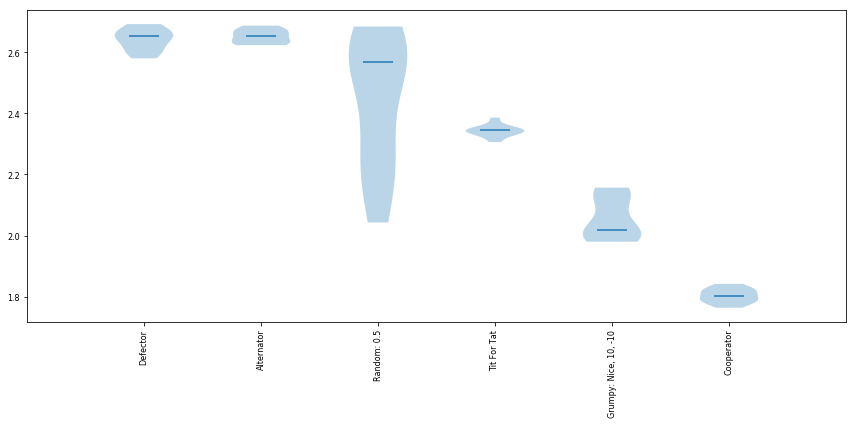
results = tournament.play()
winners = results.ranked_names
winners
Playing matches: 100%|██████████| 21/21 [00:00<00:00, 43.25it/s]
Analysing: 100%|██████████| 25/25 [00:00<00:00, 173.58it/s]
['Defector',
'Alternator',
'Random: 0.5',
'Tit For Tat',
'Grumpy: Nice, 10, -10',
'Cooperator']
scores = results.scores
scores
[[1794, 1809, 1821, 1824, 1788, 1788, 1842, 1782, 1821, 1764],
[2656, 2608, 2684, 2580, 2656, 2692, 2628, 2660, 2600, 2648],
[2586, 2206, 2265, 2043, 2567, 2595, 2262, 2604, 2570, 2684],
[2351, 2328, 2336, 2306, 2352, 2347, 2335, 2346, 2343, 2386],
[2019, 2157, 2118, 2155, 2003, 2004, 2118, 1998, 2016, 1980],
[2658, 2661, 2623, 2675, 2630, 2646, 2636, 2675, 2687, 2623]]
%matplotlib inline
plot = axl.Plot(results)
p = plot.boxplot()
p.show()
/Users/dereksnow/anaconda/envs/py36/lib/python3.6/site-packages/matplotlib/figure.py:418: UserWarning: matplotlib is currently using a non-GUI backend, so cannot show the figure
"matplotlib is currently using a non-GUI backend, "
Human strategy is a strategy which asks the user to input a move rather than deriving its own action. The history of the match is also shown in the terminal, thus you will be able to see the history of the game.
%matplotlib inline
import axelrod as axl
import matplotlib
matplotlib.style.use('classic') # Use the classic style which is what the original logo was built with
from PIL import Image
players = [axl.Cooperator(), axl.TitForTat(), axl.Alternator(), axl.Defector(), axl.Random()]
tournament = axl.Tournament(players)
results = tournament.play()
eco = axl.Ecosystem(results)
eco.reproduce(35) # Evolve the population over 100 time steps
Playing matches: 100%|██████████| 15/15 [00:00<00:00, 41.97it/s]
Analysing: 100%|██████████| 25/25 [00:00<00:00, 220.69it/s]
This shows that you are fine if you tit for tat from the get go, or even defect untill someone recirpriocates then you tit for tat. This is quite natural and normally happens by iteself.
plot = axl.Plot(results)
stackplot = plot.stackplot(eco, logscale=False);
stackplot.savefig("logo-raw.png", dpi=400)

# Python 3
%matplotlib inline
import random
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import axelrod as axl
plt.rcParams['figure.figsize'] = (10, 10)
# Two Zero-Determinant Strategies
player1 = axl.ZDGTFT2()
player2 = axl.ZDSet2()
matches = 1000
turns = 100
scores = []
for i in range(matches):
match = axl.Match((player1, player2), turns)
results = match.play()
scores.append(list(zip(*match.scores())))
scores1, scores2 = zip(*scores)
sns.tsplot(scores1)
sns.tsplot(scores2, color="y")
plt.xlabel("Turns")
plt.ylabel("Mean Scores per turn")
/Users/dereksnow/anaconda/envs/py36/lib/python3.6/site-packages/seaborn/timeseries.py:183: UserWarning: The tsplot function is deprecated and will be removed or replaced (in a substantially altered version) in a future release.
warnings.warn(msg, UserWarning)
Text(0,0.5,'Mean Scores per turn')

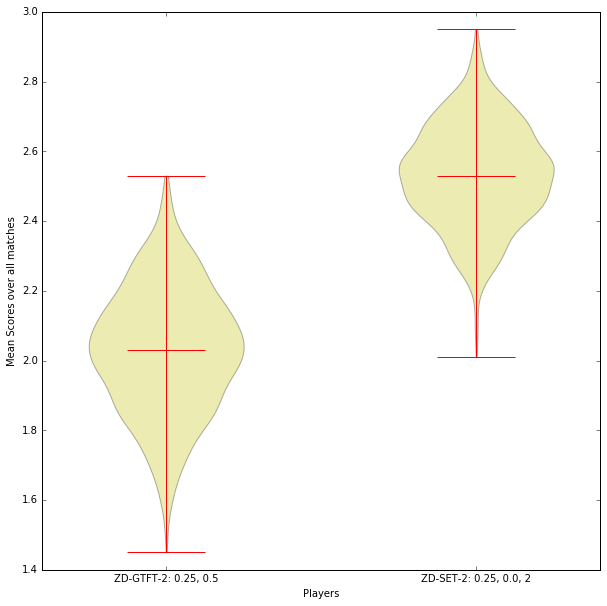
# Two Zero-Determinant Strategies
player1 = axl.ZDGTFT2()
player2 = axl.ZDSet2()
scores = []
for i in range(matches):
match = axl.Match((player1, player2), turns)
results = match.play()
# Sum the scores from the match for each player
scores.append(np.sum(match.scores(), axis=0) / float(turns))
df = pd.DataFrame(scores)
df.columns = ["Player1", "Player2"]
df.mean()
plt.violinplot(df[["Player1", "Player2"]].as_matrix(), showmedians=True)
plt.xticks([1,2], [str(player1), str(player2)])
plt.ylabel("Mean Scores over all matches")
plt.xlabel("Players")
Text(0.5,0,'Players')
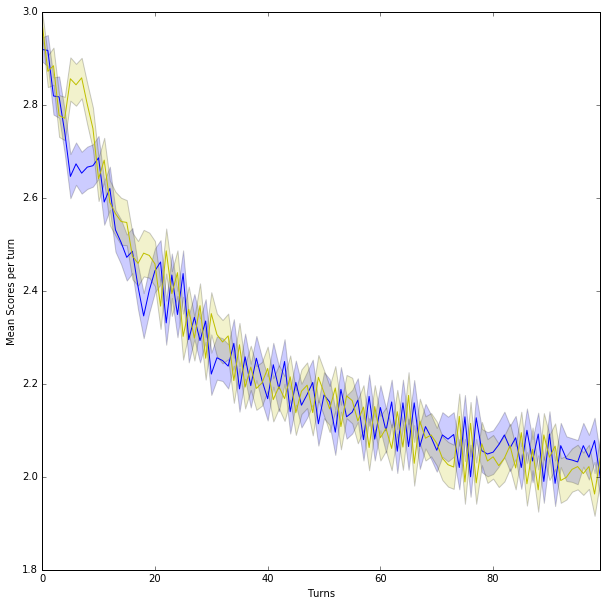
Let’s see how a little stochastic noise affects these plots. Without noise these next two strategies would always cooperate, and so both always score 3 points in each round. Instead they are driven toward mutual defection.
# Two typically deterministic strategies
player1 = axl.OmegaTFT()
player2 = axl.TitForTat()
scores = []
for i in range(matches):
match = axl.Match((player1, player2), turns, noise=0.05) # 5% noise
results = match.play()
scores.append(list(zip(*match.scores())))
scores1, scores2 = zip(*scores)
sns.tsplot(scores1)
sns.tsplot(scores2, color="y")
plt.xlabel("Turns")
plt.ylabel("Mean Scores per turn")
/Users/dereksnow/anaconda/envs/py36/lib/python3.6/site-packages/seaborn/timeseries.py:183: UserWarning: The tsplot function is deprecated and will be removed or replaced (in a substantially altered version) in a future release.
warnings.warn(msg, UserWarning)
Text(0,0.5,'Mean Scores per turn')
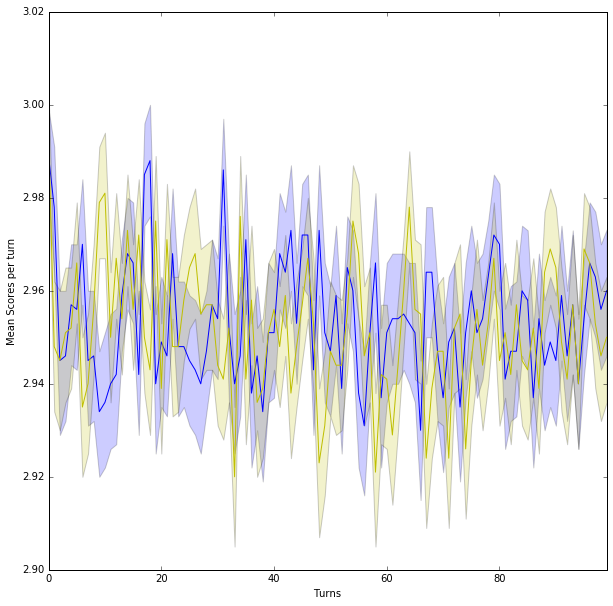
Here we see that WinStayLoseShift is able to recover from the occasional defection due to noise to maintain mutual cooperation.
# Two typically deterministic strategies
player1 = axl.WinStayLoseShift()
player2 = axl.WinStayLoseShift()
scores = []
for i in range(matches):
match = axl.Match((player1, player2), turns, noise=0.01) # 5% noise
results = match.play()
scores.append(list(zip(*match.scores())))
scores1, scores2 = zip(*scores)
sns.tsplot(scores1)
sns.tsplot(scores2, color="y")
plt.xlabel("Turns")
plt.ylabel("Mean Scores per turn")
/Users/dereksnow/anaconda/envs/py36/lib/python3.6/site-packages/seaborn/timeseries.py:183: UserWarning: The tsplot function is deprecated and will be removed or replaced (in a substantially altered version) in a future release.
warnings.warn(msg, UserWarning)
Text(0,0.5,'Mean Scores per turn')
The Moran process is a common population model of natural selection. With the wealth of strategies in the axelrod library, implementing a Moran process is simple.
The basic idea of the model is that we have a population of $N$ individuals. The population size is fixed throughout. Each round every player interacts with every other player, in this case the default game in the axelrod library, the prisoner’s dilemma.
After the scores are summed for each player, we choose one to reproduce proportionally to its score (fitness proportionate selection). We also choose one player to replace, at random uniformly. The process continues until the population consists of a single type (fixation).
The Moran process is natively supported in the axelrod library. It is amazing how much randomness protrudes and randomness can wipe out that what could have been preceived as good. Nature does not just select for what is good it also selects for what is lucky, as luck and unluck can expose the position of that which is good. Sometimes the bully gets defeated withing the first 10 iterations, the questions is how does this look when you play it out hundreds of times.
%matplotlib inline
import itertools
import random
import matplotlib.pyplot as plt
import axelrod as axl
plt.rcParams['figure.figsize'] = (10, 10)
# Create a population of size 30
N = 20
players = []
for _ in range(N):
player = random.choice(axl.basic_strategies)
players.append(player())
# Run the process. Eventually there will be only
# one player type left.
mp = axl.MoranProcess(players=players, turns=200)
mp.play()
print("The winner is:", mp.winning_strategy_name)
# Plot the results
player_names = mp.populations[0].keys()
plot_data = []
labels = []
for name in player_names:
labels.append(name)
values = [counter[name] for counter in mp.populations]
plot_data.append(values)
domain = range(len(values))
plt.stackplot(domain, plot_data, labels=labels)
plt.legend()
plt.xlabel("Rounds")
plt.ylabel("Number of Individuals")
plt.show()
The winner is: Win-Stay Lose-Shift: C

Depending on the players, your strategy should change.
### The same game played again, you will see tit for tat come up a lot,
### shows you the imporance of reciprocity.
# Create a population of size 30
N = 20
players = []
for _ in range(N):
player = random.choice(axl.basic_strategies)
players.append(player())
# Run the process. Eventually there will be only
# one player type left.
mp = axl.MoranProcess(players=players, turns=200)
mp.play()
print("The winner is:", mp.winning_strategy_name)
# Plot the results
player_names = mp.populations[0].keys()
plot_data = []
labels = []
for name in player_names:
labels.append(name)
values = [counter[name] for counter in mp.populations]
plot_data.append(values)
domain = range(len(values))
plt.stackplot(domain, plot_data, labels=labels)
plt.legend()
plt.xlabel("Rounds")
plt.ylabel("Number of Individuals")
plt.show()
The winner is: Tit For Tat
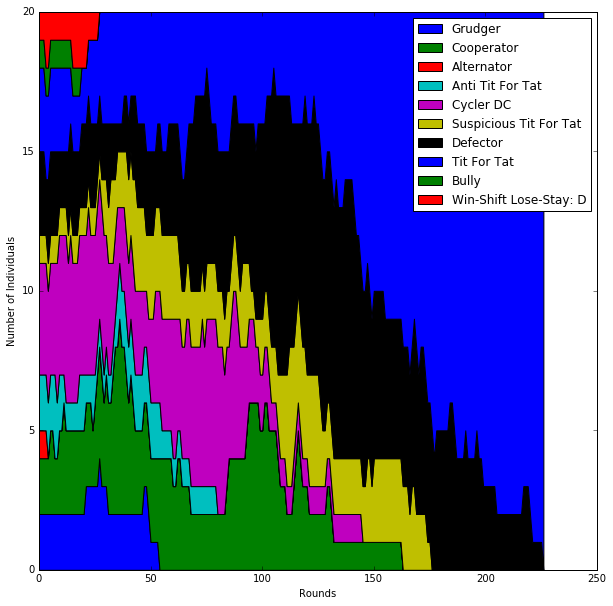
We can also run a population with mutation. It will never converge so we need to limit the number of rounds. I guess with the mutation strategy, overall area size is more important
# Create a population of size 30
N = 25
players = []
for _ in range(N):
player = random.choice([axl.TitForTat, axl.Cooperator, axl.Defector])
players.append(player())
rounds = 1000
mp = axl.MoranProcess(players=players, turns=200, mutation_rate=0.05)
list(itertools.islice(mp, rounds))
print("Completed {} rounds.".format(rounds))
Completed 1000 rounds.
# Plot the results
player_names = mp.populations[0].keys()
plot_data = []
labels = []
for name in player_names:
labels.append(name)
values = [counter[name] for counter in mp.populations]
plot_data.append(values)
domain = range(len(values))
plt.stackplot(domain, plot_data, labels=labels)
plt.legend()
plt.xlabel("Rounds")
plt.ylabel("Number of Individuals")
plt.show()

Here we will be performing a circle tournament. Ten random players are selected by the list of strategies in Axelrod. Afterwards these players are allocated into a circle network where each player competes with their two neughboors. Then we plot the results.
# Python 3
%matplotlib inline
import matplotlib.pyplot as plt
import random
# package for creation and visuliazation of networks
import networkx as nx
import axelrod as axl
strategies = [s() for s in axl.ordinary_strategies]
players = random.sample(strategies, 10)
G = nx.cycle_graph(len(players))
pos = nx.circular_layout(G)
# for the nodes
nx.draw_networkx_nodes(G,pos,
node_color='r',
node_size=100
)
# for the edges
nx.draw_networkx_edges(G,pos,
width=5, alpha = 0.5)
# using labels
labels={}
for i in range(len(players)):
labels[i]= '%s' % (players[i])
nx.draw_networkx_labels(G,pos,labels,font_size=10)
plt.show()
/Users/dereksnow/anaconda/envs/py36/lib/python3.6/site-packages/networkx/drawing/nx_pylab.py:522: MatplotlibDeprecationWarning: The is_string_like function was deprecated in version 2.1.
if not cb.is_string_like(edge_color) \
/Users/dereksnow/anaconda/envs/py36/lib/python3.6/site-packages/networkx/drawing/nx_pylab.py:543: MatplotlibDeprecationWarning: The is_string_like function was deprecated in version 2.1.
if cb.is_string_like(edge_color) or len(edge_color) == 1:
/Users/dereksnow/anaconda/envs/py36/lib/python3.6/site-packages/networkx/drawing/nx_pylab.py:724: MatplotlibDeprecationWarning: The is_string_like function was deprecated in version 2.1.
if not cb.is_string_like(label):
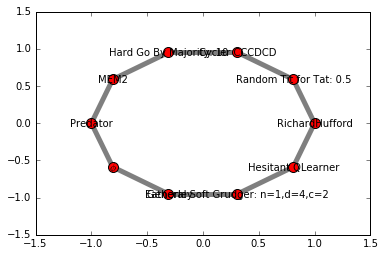
edges = G.edges()
tournament = axl.Tournament(players, edges=G.edges(), repetitions=1)
results = tournament.play(processes=1)
results.ranked_names
Playing matches: 100%|██████████| 10/10 [00:00<00:00, 1039.27it/s]
Analysing: 4%|▍ | 1/25 [00:00<00:02, 8.82it/s]/Users/dereksnow/anaconda/envs/py36/lib/python3.6/site-packages/axelrod/result_set.py:363: RuntimeWarning: invalid value encountered in true_divide
sum(map(np.array, self.match_lengths))]
Analysing: 100%|██████████| 25/25 [00:00<00:00, 12.34it/s]
['RichardHufford',
'Cycler CCCDCD',
'General Soft Grudger: n=1,d=4,c=2',
'Predator',
'Random Tit for Tat: 0.5',
'Eatherley',
'Hesitant QLearner',
'$\\phi$',
'Hard Go By Majority: 10',
'MEM2']
plot = axl.Plot(results)
plot.boxplot();
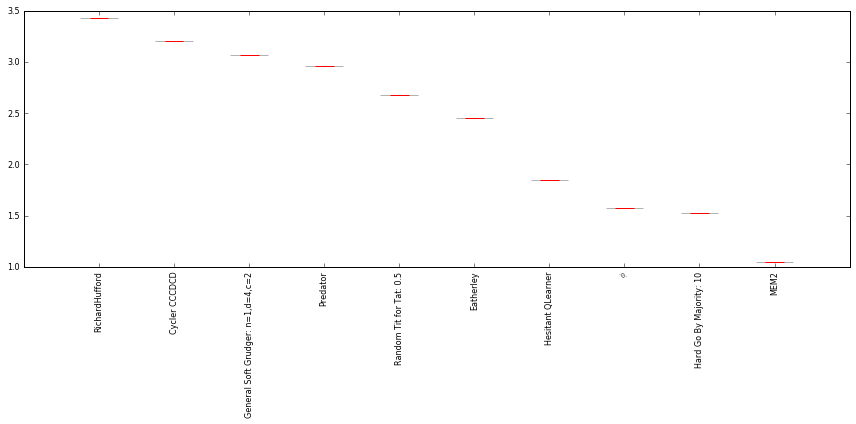
That is really interesting, reinforcement learning would beat most strategies and these games are analogouse to life as you can put them against all human known strategies, and further what happens when you put two machines against eachother.
We present tournament results and several powerful strategies for the Iterated Prisoner’s Dilemma created using reinforcement learning techniques (evolutionary and particle swarm algorithms). These strategies are trained to perform well against a corpus of over 170 distinct opponents, including many well-known and classic strategies. All the trained strategies win standard tournaments against the total collection of other opponents. The trained strategies and one particular human made designed strategy are the top performers in noisy tournaments also.